漢語成語知識庫的建構(gòu)理念與新進展
王雷 俞士汶 朱學鋒 羅鳯珠 砂岡和子 姜柄圭
摘要:在漢語中,成語是非常特殊的一個組成部分,其歷史悠久、形態(tài)穩(wěn)定、結(jié)構(gòu)固定且多用比喻義。本文以描述漢語成語的特點為起點,詳細辨析了成語、熟語、習語等多詞表達的共同點和差別,給出了漢語成語面向中文信息處理的準確定義。重點介紹了北京大學計算語言學研究所建設的漢語成語知識庫。作為一個重要的漢語語言資源,成語知識庫除了能在機器翻譯、機器輔助翻譯、跨語言檢索等自然語言處理任務中發(fā)揮重要作用外,它還對漢語語言學研究、對外漢語教學以及語言對比研究等工作也有重要的指導意義。
關鍵詞:漢語成語知識庫;建構(gòu)理念;新進展
Principle and New Development of Constructing Chinese Idiom Knowledge Base
Lei Wang1,2Shiwen Yu1Xuefeng Zhu1Fengju Lo3Kazuko Sunaoka4 Byeongkwu Kang5
Key Laboratory of Computational Linguistics of Ministry of Education1
Department of English of Peking University Beijing 1008712
Department of Chinese Linguistics & Literature of Yuan Ze University Taiwan 320033
School of Political Science and Economics of Waseda University Tokyo 16980504
Sogang University5
Abstract: Idioms are distinctive in Chinese for its long history, fixed constitution, continuity and metaphorical meaning in its context. This paper starts with a description of the characteristics of Chinese idioms and analyzes the similarities and differences of multi-word expressions such idioms, idiomatic expressions and phrases, which results in a clear definition of Chinese idioms for the purpose of Chinese information processing. We focus on a Chinese idiom knowledge base built by the Institute of Computational Linguistics at Peking University. As an important Chinese language resource, our idiom knowledge base will not only play a major role in NLP tasks such as machine translation,computer-aided translation, but also provides valuable assistance to cross-language research, linguistic research, teaching Chinese as a foreign language etc.
Key words:Chineseidiom knowledge base; principle of construction;new development
1.引言
成語在語言表達中有生動簡潔、形象鮮明、喻義深刻的特點,本身蘊含著豐富的歷史、社會和文化知識,是一個民族語言最具有特色的組成部分。漢語歷史悠久,大部分成語是從古代歷史典故、寓言傳說、經(jīng)典文獻中相承沿用下來的,通常有著幾千年的歷史,是珍貴的民族文化遺產(chǎn);此外,漢語成語數(shù)量多,使用頻率高,這也是漢語不同于其他語言的一個顯著特點。在語言教學中,成語教學是不可忽視的重要組成部分,教好、學好成語可以使學生掌握有關成語的社會、歷史和文化知識,開闊眼界,提高表達、閱讀和寫作能力[1]。在漢語中,成語占有非常重要的地位,研究類似成語、習語、諺語等多詞表達(Multi-word Expression)并建設這種語言單位的知識庫對于語言教學[2]、詞典編纂[3]、自然語言處理[4]等領域的研究和發(fā)展會具有實質(zhì)性的意義。近年來隨著中文電化教學理論日益發(fā)展,相關實踐與方法日益得到推廣與普及,大規(guī)模、高質(zhì)量的漢語語言知識庫(包括各種形式的語料庫)不斷開發(fā)研制出來并應用于實際語言教學中,這些因素對于推動漢語文教學、對外漢語教學起了非常大的作用。
此外,隨著互聯(lián)網(wǎng)的普及,搜索引擎已經(jīng)逐漸成為人們學習、工作乃至日常生活的一部分。遇到問題,一些人首先想到用搜索引擎搜索一下,但是當前搜索引擎的能力和表現(xiàn)都還不能盡如人意。在進行搜索時,搜索對象限定為網(wǎng)頁中用字符串表示的文字,而我們真正要搜索的是其表達的內(nèi)容,并不是文字符號串本身。當搜索引擎嘗試對類似于成語這樣有固定組成結(jié)構(gòu)的多詞表達進行深入的語法、語義分析時,效果并不理想。因此從機器理解自然語言的角度,深入研究類似詞組、習語、成語、諺語等這樣的多詞表達對于自然語言處理技術的提升會具有實質(zhì)性的意義;而中文信息處理尤其需要大規(guī)模、高質(zhì)量的、具有固定結(jié)構(gòu)的詞組、習語、成語等語言知識庫的支持。
2.現(xiàn)代漢語中的成語及其特點
根據(jù)《現(xiàn)代漢語詞典》[5],漢語成語的定義為“人們長期以來習用的、簡潔精辟的定型詞組或短語。”其中“習用”一詞表明成語須具有一定的歷史淵源,亦有一個演變過程,通常時代感較強。從結(jié)構(gòu)上看,成語書面語言用字較多,通常以四字格的形式出現(xiàn),而其中“2+2“的聯(lián)合結(jié)構(gòu)又占大多數(shù)。從語義角度來看,正是由于成語具有“簡潔精辟”的特點,導致其較普通詞語難懂。有些可根據(jù)字面意義推斷,有些必須知道來源或典故才能懂得其含義。描述性成語一般情感色彩比普通詞語強,感情表達強烈。從修辭的角度看,很多成語具有隱喻,具有生動形象,寓意深刻的特點。從使用情況上看,中國國家語言文字工作委員會自2006年起,每年發(fā)布的《中國語言生活狀況報告》,都包含各種媒體使用成語的情況。如在2011年的10億漢字的語料中,成語出現(xiàn)近200萬次,覆蓋率為0.32%。
但是如果我們仔細觀察上述對成語的定義,我們發(fā)現(xiàn)其只是一個描述性的定義,存在模糊性。如何給漢語成語下一個精確的定義,無論是從語義、語法還是語用的角度,一直都是一個難題。在引入多詞表達概念之前,漢語對于一些難以明確定義為成語的這類固定結(jié)構(gòu)也稱為“熟語”或者“習語”。《現(xiàn)代漢語詞典》對于“熟語”的定義為:固定的詞組,只能整個應用,不能隨意變動其中成分,并且往往不能按照一般的構(gòu)詞法來分析,如“慢條斯理、無精打采、不尷不尬、一來二去、亂七八糟、八九不離十等。”[6]在一部有關“習語”的專著中,將其定義為:一種多詞的語言單位,常為習慣用法,具有相對固定的句法-—語義結(jié)構(gòu)。語言的使用者慣于將它作為一個整體來用,以增強語體效果。總體上,語言學家們對于熟語的一些特點達成了共識。文獻[7]認為,熟語是語言中定型的詞組和句子,使用時一般不能任意改變其組織,包括成語、諺語、格言、歇后語等。文獻[8]認為,詞匯當中,除了許多獨立運用的詞以外,還有一些固定詞組為一般人所經(jīng)常使用的,也作為語言的建筑材料和詞匯的組成部分,這些總稱熟語。熟語的范圍相當廣,包括慣用語、成語、歇后語、諺語、格言等。
從以上描述中我們看到,“固定性”是這類語法結(jié)構(gòu)的共同特點,而且熟語應該包含成語。不承認熟語(或按英語稱為“多詞表達”)的固定性,在自然語言處理任務中會出現(xiàn)很多問題。例如對漢語文本中的句子進行分詞,一些成語或者熟語如果按照組成成分進行切分和標注,將會給理解造成很大的困難。例如漢語成語“雞飛狗跳”,我們用ICTCLAS 進行切分并標注會得到以下結(jié)果:
雞/n? 飛/v? 狗/n? 跳/v
而實際上這個成語只是利用兩種動物“雞”和“狗”來進行比喻,本身并非和這兩種動物相關,把它切分開來會讓人覺得這個成語的語義和這兩種動物相關。再如諺語“只要功夫深,鐵杵磨成針。”同樣切分后的結(jié)果為:
只要/c? 功夫/n? 深/a? ,/w
鐵杵/n? 磨/v? 成/v? 針/n? 。/w
也容易讓人無法得到該諺語的真正含義。
問題在于熟語和成語的界限究竟在哪里?我們認為,漢語成語的定義應該符合國際通用的對成語的定義[9]:An idiom is a multi-word expression that has a figurative meaning that is comprehended in regard to a common use of that expression that is separate from the literal meaning or definition of the words of which it is made.如其所言,是否歸入成語關鍵是該多詞表達的語義不能從其組成成分——無論是字還是詞——中推測出來,亦即無法從成語的字面知道其比喻義。這樣漢語中“杯弓蛇影”為成語,而“興高采烈”則不是。
3.現(xiàn)代漢語成語知識庫的建設理念
人學習第二語言要掌握大量語法、語義知識,讓計算機理解人類語言,也要給計算機配備語言知識庫,使之成為計算機處理語言的知識基礎和依據(jù)。而給計算機用的語言知識與給人學習的語言知識是要有區(qū)別的。針對利用計算機對自然語言進行處理,主要要解決三個問題:一、計算機需要什么樣的語言知識?二、怎樣描述這些語言知識,計算機才能接受?三、如何建設實用型語言知識庫以便讓計算機能夠方便地處理這些知識?
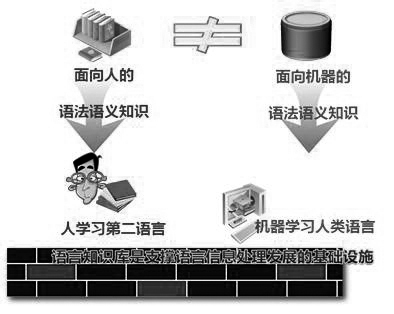
圖1 語言知識庫是支撐語言信息處理發(fā)展的基礎設施
在自然語言處理領域中,語言知識庫就好比人類大腦中存儲語言知識的記憶區(qū)域,是支撐語言信息處理發(fā)展的基礎設施(如圖1所示)。恰當?shù)闹R表示、快速有效的存儲與讀取機制、靈活高效的算法等都構(gòu)成了計算機用語言知識庫的必要要素。因此語言知識庫是自然語言處理系統(tǒng)中不可或缺的組成部分,是這類系統(tǒng)成敗的關鍵。在用語言知識庫搭建的平臺上可以上演威武雄壯生動活潑的應用系統(tǒng)的劇目(圖2)。
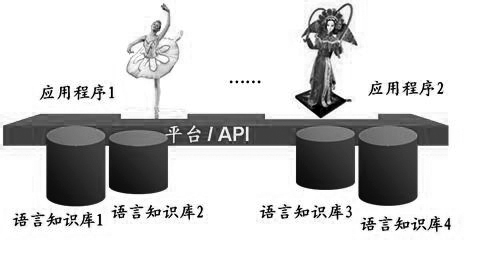
圖2 應用程序需要建立在語言知識庫的平臺上
從上世紀八十年代起二十六年來,北京大學計算語言學研究所(以下簡稱“計算語言學所”)立足北大文理結(jié)合的基礎,發(fā)揮對母語知識和文化的認知優(yōu)勢,日積月累,終于建成綜合型語言知識庫(Comprehensive Language Knowledge Base,以下簡稱“CLKB”)。CLKB的語言知識覆蓋詞、詞組、句子、篇章各級語言單位和詞法、句法、語義各個知識層面,從漢語向多語言輻射,從通用領域深入到專業(yè)領域[10]。一直以來,綜合型語言知識庫沒有停止發(fā)展。已有的知識庫的瑕疵不斷被剔除,質(zhì)量不斷提高。新的知識庫也在建造中。應用也在不斷推進 。
對于針對漢語成語構(gòu)建相應的語言知識庫,俞士汶教授曾指出:“成語在現(xiàn)代漢語中頻繁出現(xiàn),對成語的理解(包括確切翻譯)是文本內(nèi)容理解的一個重要組成部分。成語龐大,畢竟有限;成語難懂,畢竟可查。只要建設好成語知識庫,絕大部分成語的理解問題就會迎刃而解。”正是認識到了文本中成語理解的重要性,他提出了構(gòu)建成語知識庫的設想,并在國家重點基礎研究課題(973)“文本內(nèi)容理解的數(shù)據(jù)基礎”(課題編號:2004CB318102)中實踐了這一主張,建成了一個漢語成語知識庫,并基于該成語知識庫開展了多詞表達、比較語言學以及計算機輔助翻譯方法的研究。在國家973課題的支持下,計算語言所構(gòu)建了漢語成語知識庫(Chinese Idiom Knowledge Base,以下簡稱“CIKB”)。
4.成長中的成語知識庫
計算語言學所構(gòu)建的漢語成語知識庫,其發(fā)展歷程共分三個階段。第一階段(1986年—2003年)所搜集標注的成語是作為《現(xiàn)代漢語語法信息詞典》 (以下簡稱“語法信息詞典”)的組成部分。當時《語法信息詞典》收了8萬余漢語詞語,其中包含的成語和習語共有9000多條(見圖3)。清華大學出版社出版了介紹這部電子詞典的專著[11]。
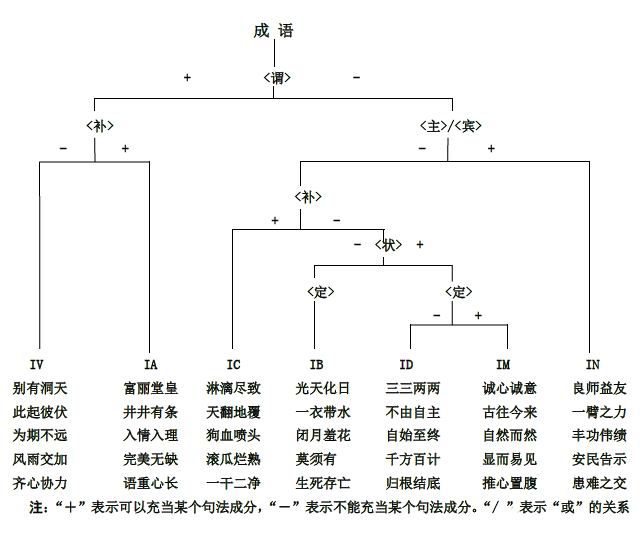
圖3 《語法信息詞典》中所收錄的成語語法屬性標注
發(fā)展的第二階段(2004年—2009年)是在973課題中所提出的“綜合型語言知識庫”的規(guī)劃下,單獨建庫。收入成語及熟語36000多條。其中除《語法信息詞典》原有的“主語”、“謂語”、“句首”等句法屬性信息外,增設了11個新的屬性字段:成語、級別、變體、近義、反義、直譯、意譯、英語近似、譯者、釋義、詞頻、來源。至此,成語知識庫中共計有23個屬性字段。特別是“直譯”、“意譯”、“英語近似”字段(見圖4)既重要,又難填。現(xiàn)已完成1萬多條成語完整的屬性值填寫,其中英語字段自譯的就有2600多條。

圖4 成語知識庫中英譯字段標注示例
發(fā)展的第三階段(2010年—至今)緣于計算語言學所與臺灣元智大學合作的“歷代語言知識庫建置”計劃。自2010年加入“歷代語言知識庫建置”計劃起,成語知識庫的發(fā)展有了更開闊的視野,更加重視成語知識庫在漢語教學特別是東亞地區(qū)的漢語教學領域所能發(fā)揮的潛能。其進展如下:(1)成語知識庫與歷代語言知識庫中的另一成果“詩詞曲典故資料庫”進行連接,相互參照。兩個知識庫中實現(xiàn)成員的優(yōu)勢互補,提高知識庫整體品格。例如條目“傾城傾國”經(jīng)過與典故資料庫進行影射可以得到如“傾國風流、一顧傾城、名花傾國、傾人城、傾城色、傾城國”等古詩詞和文學作品中的典故。成語與典故的對應使兩個自立的知識庫交相輝映,可以讓學習者同時領悟成語與典故的含義,不僅有助于理解使用成語的漢語文本的內(nèi)容,還能增強賞析中國古典文學瑰寶的能力。(2)建設了成語典故分階多語教學網(wǎng)站。網(wǎng)站的內(nèi)容比較豐富,例如進行了成語形態(tài)對比與教學關系的探討 (見圖5)。漢語的“走馬看花”,韓語是“走馬看山”,漢語的“異口同聲”日語是“異口同音”,詞匯組成成分不同。漢語的“堂堂正正”,而日、韓語中的形態(tài)是“正正堂堂”,意義相同而詞序不同;日語同時用[正々堂々]的寫法,讀音則為“せいせいどうどう(seiseidoudou)”;韓語的寫法“正正堂堂”,讀音則是“????(jungjung dang dang)”。

圖5 成語知識庫中多語形態(tài)比較示例
(3)進行了基于成語知識庫的漢語成語教學實踐活動。其中包括王雷著《中國成語1000(漢英對照)》[13]以及發(fā)表的相關漢語成語知識庫與漢語教學的論文[1]。
5.結(jié)語與未來研究
目前,無論是從人的角度還是從機器的角度,成語的理解與運用還存在一定的困難。例如,成語中包含的非常用字:另辟蹊徑、高屋建瓴、言簡意賅、錙銖必較、罄竹難書……;含費解的詞:膏火自煎、烏合之眾、獨具匠心、固若金湯、司空見慣、格物致知……;隱喻的廣泛使用:洛陽紙貴、罄竹難書、一絲不茍、金屋藏嬌等。一些成語與歷史典故關系密切,在應用時非常依賴語境,稍加不注意就可能造成應用不當甚至是錯誤。例如:胸有成竹、金屋藏嬌、朝三暮四、杯弓蛇影、班門弄斧……等等。
基于成語知識庫所開展的研究可以分為兩個角度,從小視野來看主要是成語的理解與運用,尤其是面向中文信息處理的應用,從而做到既面向機器又面向人,以面向人的研究為基礎,以機器自動理解為最終目標,兩者相輔相成、相互促進。從大視野來看,則須緊扣歷代語言知識庫的構(gòu)建,對歷代漢語語言知識進行深層次的分析和研究,探索漢語言演化規(guī)律與社會環(huán)境變遷的交互影響。
為了支持成語知識庫繼續(xù)發(fā)展,計算語言學所也制定了一些新計劃,其中包括:1)中國國家自然科學基金項目“隱喻識別與理解的理論與方法研究”(2012年-2015年,王治敏博士主持,俞士汶?yún)⒓樱?)中國國家自然科學基金項目“漢語全文詞義標注關鍵技術研究”(2013年-2016年,曲維光教授主持,朱學鋒參加);3)北京大學計算語言學中國教育部重點實驗室開放課題“漢語和英語多詞表達中的隱喻研究”(2013年起,王雷主持)。
成語知識庫是一項已歷時二十余年的大型語言工程,建構(gòu)的全過程都采用人機互助的方法。自動建構(gòu)本質(zhì)上是機器輔助構(gòu)建,盡可能采用適用的成熟的軟件技術,如數(shù)據(jù)庫技術,機器學習技術等等,可以保證工程的規(guī)模和進度。同時,成語知識庫又是一項知識密集型的高級語言工程。單純依賴自動技術建構(gòu)的語言知識庫的質(zhì)量不能滿足應用的需要,因此必須投入相當多的人力,必須投入高水平的專家的力量。專家的知識和奉獻才是語言知識庫質(zhì)量的保證。
致謝
本研究工作得到國家自然科學基金(項目編號61170163,61272221, 蔣經(jīng)國基金會(2009)以及北京大學計算語言學教育部重點實驗室開放課題(項目編號201302)。得到國家高科技研究與發(fā)展項目(863項目)(項目編號 2012AA011101)部分支持。
參考文獻
[1] 王雷,俞士汶,朱學鋒,羅鳳珠,漢語成語知識庫與漢語教學[A],第八屆中文電化教學國際研討會論文集,第83-89頁,2012
[2] Lo, Wing Huen. Best Chinese Idioms (Vol. 3)[M]. Hong Kong: HaiFeng Publishing Co,1997: 20-38.
[3] Fellbaum, Christiane. Idioms and Collocations: Corpus-based Linguistic and Lexicographic Studies (Research in Corpus and Discourse)[M]. London: Continuum International Publishing Group Ltd.2007:157-196.
[4] Lin, Dekang. Automatic Identification of NoncompositionalPhrases[A]. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics[C].1999. Maryland, USA: 317-324.
[5] Fiedler, S.. English Phraseology: A Coursebook[M]. Turbingen: Gunter NarrVerlag(2007).
[6] 社科院詞典編輯室,現(xiàn)代漢語詞典(第三版)[M],北京:商務印書館,1998
[7] 辭海編輯委員會,辭海(1979年版)[M],上海:上海辭書出版社,1979
[8] 胡裕樹. 現(xiàn)代漢語[M] . 上海: 上海教育出版社,1998.
[9] McArthur, Tom. 1992. The Oxford Companion to the English Language[M]. Oxford University Press, Oxford, UK.
[10] 俞士汶,穗志方,朱學鋒. 綜合型語言知識庫及其前景[J]. 中文信息學報,第二十五卷第六期. 2011年11月:12-20.
[11] 俞士汶,朱學峰,王惠.《現(xiàn)代漢語語法信息詞典詳解(第二版)》[M].北京:清華大學出版社,2003:51.
[12] 中國工程院編,《20世紀我國重大工程技術成就》[M],廣州:暨南大學出版社,2002年,第一版31頁
[13] 王雷.《中國成語1000(漢英對照)》[M].北京大學出版社, 2011:65-86.
-
作者單位
-
北京大學計算語言學教育部重點實驗室
-
北京大學外國語學院
-
臺灣元智大學
-
中國語言文學系
-
早稻田大學政治與經(jīng)濟學院、西江大學
